I built the sync engine, not just the app on top of it.
Slipstream is a Linear-style issue tracker that works instantly offline and reconciles when the network returns. The tracker UI is the surface; the point is underneath — a local-first sync engine written from scratch, with no Replicache, no Zero, no off-the-shelf sync layer. Optimistic mutations, a server-authoritative mutation log, an offline queue that retries with backoff, and a CRDT used only where it earns its keep. Try it live — there’s a one-click demo workspace.

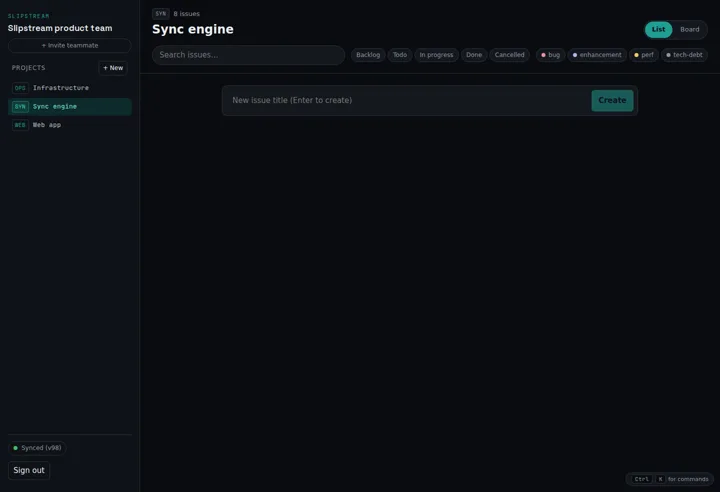
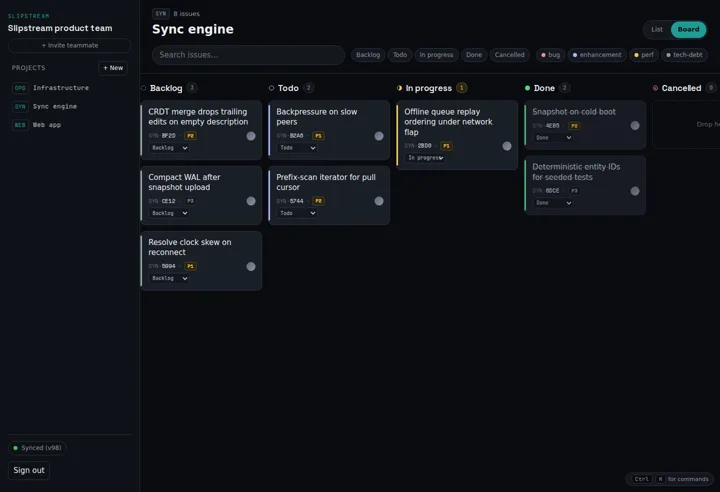
The shape of the thing
Slipstream is a pnpm + Turborepo monorepo: two apps (the Next.js 15 web client and a Hono sync
server) and three packages — protocol (Zod-validated wire types shared by both sides),
client (the sync engine itself, UI-framework-agnostic), and ui. The engine keeps
an in-memory view assembled as server base state plus unconfirmed outbox, persisted to IndexedDB
so a reload mid-outage loses nothing.
- TypeScript
- Next.js 15
- React
- Zustand
- Yjs
- IndexedDB (idb)
- dnd-kit
- TanStack Virtual
- Hono
- MongoDB
- WebSockets (ws)
- Redis presence broker
- Zod
- argon2
- Vitest
- pnpm workspaces
- Turborepo
- GitHub Actions
- Docker
How the sync engine works
Every edit is a named mutation — createIssue,
moveIssue, and so on — applied optimistically to the local view the moment you act,
then queued in a durable outbox. The same mutator functions run on the client and the server, so the
optimistic result and the authoritative result agree unless something genuinely conflicted. The server
applies pushed mutations inside a MongoDB transaction against a global version counter, giving every
mutation a total order; the client then pulls a patch, rebases its remaining outbox on top, and the
view converges. Rejected mutations simply drop out of the outbox — the server’s answer is
always the truth.
Change notification is deliberately boring: the server sends a contentless poke over a WebSocket, and the client responds by pulling over HTTP. Pokes carry no data, so a missed poke costs a moment of staleness, never correctness — the next pull always catches up. Presence (who’s online, cursors) rides the same socket through a pluggable broker: in-process for a single node, Redis pub/sub when there’s more than one.
Where the CRDT is — and isn’t: only issue descriptions use Yjs, because collaborative rich text is the one place last-write-wins genuinely destroys work. Everything else — status, priority, assignee, ordering — goes through the mutation log, where server-authoritative ordering is simpler to reason about and simpler to debug. Choosing not to CRDT everything was the most important architectural decision in the project.
The bug that only appeared with DevTools closed
The live demo shipped with a bug worth writing up: visitors saw an empty “offline” workspace,
but the moment I opened DevTools and instrumented fetch to watch the traffic, everything
worked. The instrumentation was the fix — a textbook Heisenbug. The transport class took
fetchImpl: typeof fetch = fetch as a default parameter, which captures the native
fetch unbound; calling it as this.fetchImpl(...) makes the browser see the
transport instance as the receiver and throw Illegal invocation before a single byte hits
the network. Node’s fetch doesn’t care about its receiver and the test suite
injected in-process transports, so nothing upstream ever caught it. Wrapping the default in a plain
arrow function fixed it; a regression test now stubs a receiver-sensitive fetch so it can
never come back.
The outage also exposed a resilience gap: the initial sync was one-shot, so a client whose first sync failed sat dead until a server poke that a solo session might never receive. The engine now retries failed syncs with exponential backoff (1s doubling to 30s, reset on success), and the web app treats regaining focus or network as a “try now” signal — all behind injectable scheduler seams so the backoff maths is unit-tested with fake timers, not sleeps.
The UI holds its end up
A sync engine demo is only convincing if the app feels real. The tracker has a WAI-ARIA combobox command palette (Ctrl+K), a board with full keyboard drag-and-drop via dnd-kit, virtualised lists with TanStack Virtual, and live presence avatars. Kill the network, keep working, watch the outbox counter tick down when you’re back — the whole loop is visible in the UI.
Proof over promises
The repository is public at github.com/hitenpatel/slipstream — engine, protocol and server covered by Vitest (including the backoff and receiver-binding regression tests above), CI on GitHub Actions with coverage reporting, architecture decision records for the calls that mattered (poke-over-WebSocket, CRDT scope), and a Docker Compose stack that runs the whole thing. The live instance at tracker.hiten.dev is that same stack, self-hosted.